December 8, 2023
String processing is a common part of almost all programs found on FreeBSD. Even if strings are not at the core of an application, many ancillary tasks such as parsing options, dealing with configuration files, and generating log files involve string operations.
String operations have a reputation for performing rather poorly. Instead of having an explicit length, C strings are terminated with nul characters. Routines processing such strings, such as those provided by the C standard library libc are often reduced to walking through strings character by character in search for the nul terminator.
To remedy these performance problems, the FreeBSD Foundation sponsored work to reimplement the libc string functions with SIMD techniques, speeding up string functions and conveying benefits to a wide variety of text-processing programs. An initial implementation was carried out for the amd64 architecture (also known as x86-64) using the SSE family of instruction set extensions. Being the most common architecture on which FreeBSD is used and the most widely supported set of SIMD extensions, we hope that the largest share of our user base can benefit from this initial improvement.
Work on this implementation has now concluded and is currently undergoing acceptance testing for inclusion into 15-CURRENT. The enhanced functions will then be backported for inclusion into the future
FreeBSD 14.1 release.
Technical Aspects
Over the years, the amd64 architecture has been extended with a variety of instruction set extensions, many of which are useful for improving the performance of string functions. However, only the presence of a small number of them (the “baseline” set) is guaranteed on any amd64 processor. Following the amd64 architecture levels laid out by the amd64 System V ABI, we have implemented a dispatch framework that picks the most appropriate implementation of each string function based on the architecture level supported by your CPU and what implementations are available. Being based on the ifunc mechanism, the dispatch framework has no runtime overhead after an initial call to determine which function is to be used.
Currently, most string functions have implementations for the “baseline” or “x86-64-v2” architecture levels based on the SSE family of instruction set extensions, complemented by “scalar” implementations for users who wish to opt out of SIMD-enhanced string functions altogether. Provisions have been made for future extensions to the “x86-64-v3” (AVX and AVX2) and “x86-64-v4” (AVX-512F/BW/DQ/VL) architecture levels. The architecture level used can be controlled by the new environment variable ARCHLEVEL.
An effort has been made to provide implementations for the “baseline” architecture level of almost all functions. However, some functions require instructions only added with x86-64-v2 to provide a meaningful performance benefit over the scalar implementations and consequently only have “x86-64-v2” level implementations. For other functions, we found that use of SSE does not provide a significant benefit over scalar (i.e. non-SIMD) code. For these, only scalar implementations are provided. This includes the memcpy() and memset() family of functions, for which amd64 provides specialised machine instructions that usually outperform SSE.
The following functions were directly enhanced as a part of this project:
FUNCTION SCALAR SIMD NOTES bcmp() (X) baseline memccpy() X baseline memchr() X baseline memcmp() (X) baseline memrchr() X baseline rindex() X baseline alias of strrchr() stpcpy() (X) baseline stpncpy() X baseline strcat() X indirect SIMD via strlen(), stpcpy() strchrnul() X baseline strcmp() (X) baseline strcspn() X x86-64-v2 strlcpy() indir. baseline scalar via strlen(), memcpy() strlen() (X) baseline strncmp() X baseline strrchr() X baseline strspn() X x86-64-v2 timingsafe_bcmp() X baseline timingsafe_memcmp() X --- no SIMD implementation (X): existing implementation
For some less important functions, no direct SIMD implementations are provided. Instead, the functions were reimplemented to call into functions with SIMD-enhancements, conveying a benefit without the
maintenance overhead of a dedicated SIMD implementation. This affects the following functions:
FUNCTION VIA index() strchrnul() strchr() strchrnul() strcpy() stpcy() strlcat() memchr(), strlcpy() strncat() strlen(), memccpy() strncpy() stpncpy() strnlen() memchr() strpbrk() strcspn() strsep() strcspn()
Implementation Details
Two main challenges are associated with the use of SIMD techniques for string manipulation. The first challenge is found in a prior unknown length of nul-terminated strings (C strings). The length of the string must be discovered as the string is processed; finding the string length in a first pass and then processing the string as if it was of fixed length is frequently significantly slower.
Additionally, care must be taken not to read too far past the end of the string. A string may end just before an unmapped page, crossing into which could crash the program. Thus care must be taken to never cross page boundaries before the code has ensured that the string does not end before the boundary.
This is usually achieved by only performing aligned loads from memory (which do not cross page boundaries), loading the next chunk only after having verified the absence of nul characters in the previous chunk. While this method usually works, functions like strcmp() that deal with multiple strings at once may require more complicated techniques.
The other challenge is that most strings are rather short. While SIMD routines are usually optimised for large inputs, string routines are frequently called on short strings and must perform well on these. If
a string routine is programmed with a large initial setup cost or with overly large block sizes, it may perform worse than the generic C code it replaced in the applications it is used in.
To avoid this problem, a custom benchmark framework was designed, testing string functions on inputs with average length of 16 bytes, 64 bytes, and for very long (128 kB) strings. Then, the routines were incrementally optimised for good performance across all three cases.
Benchmark Results
The benchmark results below show the performance of the various string functions on their respective microbenchmarks from our benchmark framework. The benchmarks chosen for this diagram reflect an average string length of 64 bytes with geometric distribution. Please note that the benchmarks for different functions vary in various details and the measured performance is not directly comparable.
Where FreeBSD did not have an architecture-specific implementation of a string function before, the “pre” column shows performance of the generic C code and “scalar” as well as “SSE” (for baseline/x86-64-v2) are the newly implemented functions. Otherwise, the “scalar” column refers to an existing assembly implementation complemented by a new SIMD implementation for in the “SSE” column.
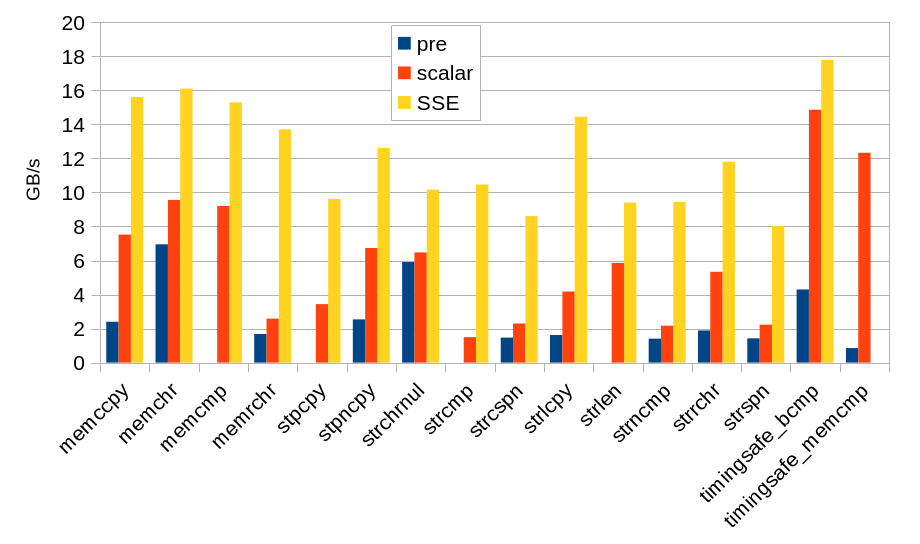
We observe that the new implementations improve the performance of the previous code by a factor of 5.54 on average. The improvements range from factors of 1.60 for strlen() to 14.5 for timingsafe_memcmp().